
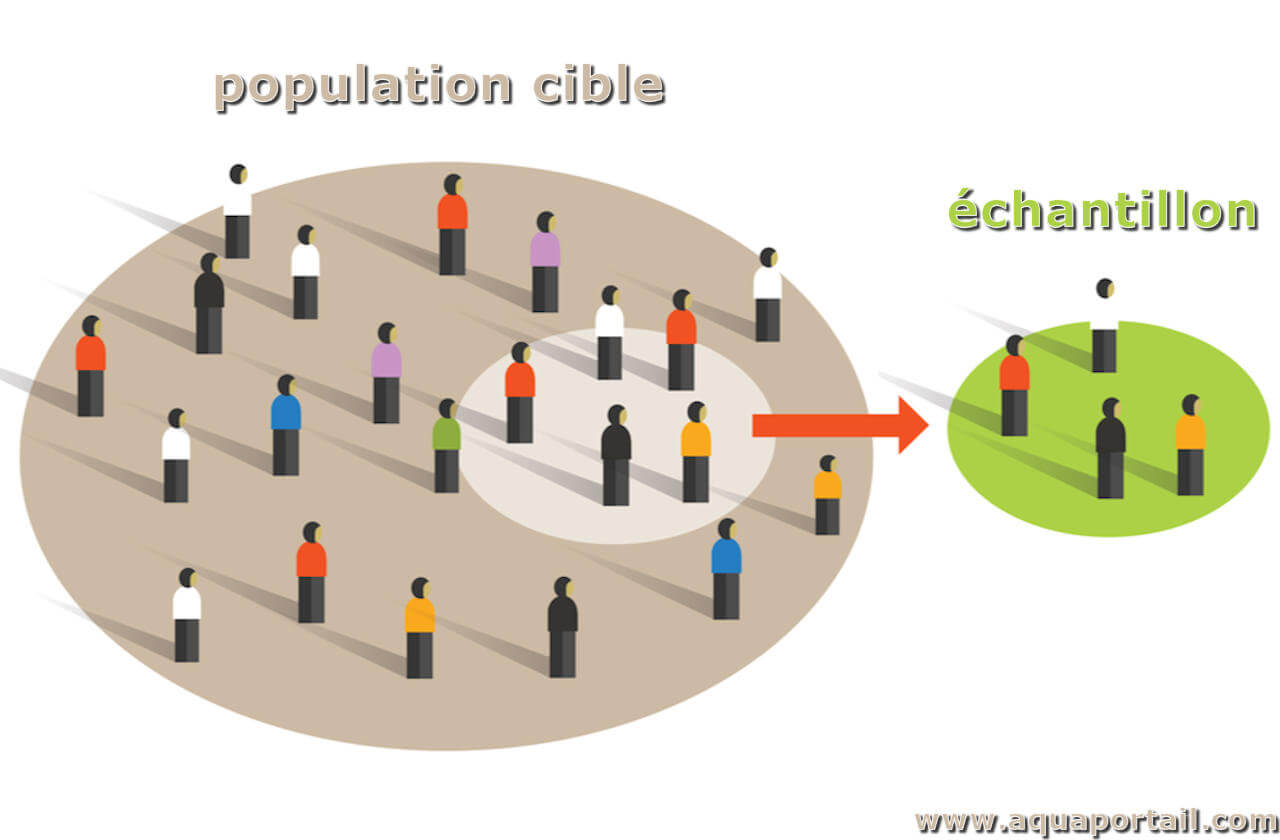
Ce n’est qu’une fois le champ défini et la population circonscrite qu’intervient la constitution de l’échantillon en lui-même : on se demande alors quelles sont les unités que l’on va interroger au sein de cette population.
Deux grandes familles d’échantillons représentatifs sont à la disposition du chargé d’étude : les échantillons probabilistes (fondés sur l’aléatoire) et les échantillons empiriques (fondés sur des quotas). Le choix entre l’un ou l’autre dépend des contraintes adossées à l’enquête (budget disponible, délais de production, etc.) mais surtout de la disponibilité (ou non) d’une base de sondage et de sa fiabilité.
Quelle va être la taille de l’échantillon, comment passer de la partie interrogée au « tout » correspondant au champ couvert par l’enquête, quels sont les biais, quelle est la marge d’erreur, de quelle taille doit être l’échantillon, comment traiter les non réponses ? Voilà l’ensemble des questions auxquelles cet enseignement se propose de répondre.
Le cours reviendra sur l’histoire des probabilités statistiques, et sur l’invention de la notion d’échantillon représentatif ; il présentera les techniques d’échantillonnage et quelques éléments de théorie des sondages ; il s’intéressera aussi à la notion d’échantillonnage du point de vue de l’enquête qualitative à travers la notion de saturation. Le cours sera illustré par des exemples et des exercices.- टीचर: Ada-Marlen Chmilevschi
- टीचर: Fabien Eloire
- टीचर: Jingyue Xing-Bongioanni